I enrolled a MOOC titled "Disasters and Ecosystems: Resilience in a Changing Climate" which is organised by the UNEP (and other organisations... which names I'm going to learn by heart cause they have like 2 minutes of credits after each lecture O_o ). Not that I know nothing about disasters, risks or climate change (I'm a geographer and ecologist after all), but I was curious about the product that was made by organisation of this class.
The third video (and first video that is not an introduction) they teach us about the disasters; differences between hazard and disaster; and risks. Well... the thing they told, the graphs they showed - that what inspired the title of this post.
Terminology
Here see some definitions they use.
Disaster. When they say "disaster" they mean "natural disaster" that was enhanced by human [mismanagement].
Risk - a potential losses due to disasters.
Hazard - A dangerous phenomenon, substance, human activity or condition that may cause loss of life, injury or other health impacts, property damage, loss of livelihoods and services, social and economic disruption, or environmental damage.
Exposure - People, property, systems, or other elements present in hazard zones that are thereby subject to potential losses.
Vulnerability - the characteristics and circumstances of a community, system or asset that make it susceptible to the damaging effects of a hazard
Fails
The risk
They presented a "great" formula for (a disaster) risk evaluation that they use in the UN:
Risk = Hazard * Exposure * Vulnerability
where: Exposure = People * ExposureTime
Vulnarability - succeptability to hazard.
Well these characteristics do correspond to the risk, but the formula is stupid! I
already wrote about that:
Risk = Probability * Damage. And this formula actually corresponds to the definition they give (see Terminology section). We can't get a monetary outcome from their formula. We can't get numeric numeric output out of that formula at all: can you multiply
flood by
people? Can you???!!!
A Disaster with Disasters
The fail with the risk evaluation is a common mistake, but the fail with disaster - that is what really cool!
Take a look at this plot (which is from reading materials from the course):
What can you conclude from this plot? That the world is doing to hell and we all will fall to disaster? Let's look closer. The exposure is growing faster for poorer countries (and it is the only conclusion they make in lecture)... but the total number of people exposed (and for each type of countries) seems to be the almost unchanged! Interesting... This means (see the definition for the exposure) that there are just a 150% increase of property value in the dangerous area of the poorer countries (and 25% for the richest) on a span of 30 years. Does this graph shows us only the economic grows? I think it does... (reminds me of
my previous post).
Now to the most delicious part. Take a look at this two graphs from the lecture readings:
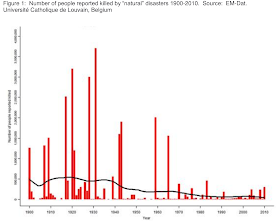 |
| Deaths dynamics |
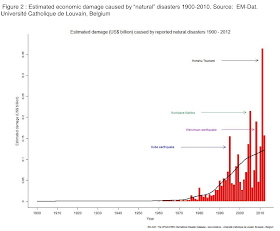 |
| Damage dynamics |
This is interesting. Despite the population growth and all that questionable "climate change" staff people die less (in total numbers), see fig. 1, but the damage increases, see fig. 2. Did they take inflation into account for the damage graph? Do not know... I think they didn't, otherwise they would use "discounted damage" term instead of just "damage" and would indicate the base year. So the second graph seems to demonstrate inflation and may be the economic grows.
Clearly disasters are not that disastrous. Despite the new on the TV on the subject the nature's wrath even enhanced by human is less and less dangerous for human lives. The pockets are to suffer: the storm in port wrecking the humble fisherman's boat or a trawler - that's the difference.
Conclusion
From these graphs I can conclude one thing - it is safer to live now than in the past, a disaster should not be feared as a deadly havoc. To my mind the disaster nowadays is entirely economic issue. See, if we loose less people and (maybe) more money - we should just develop more advanced insurance techniques to cover economic damage and relax. The disasters should just be studied as phenomena to develop cheap early warning systems, let the property be destroyed (just cover the losses with insurance) and additional employment to be created (rebuilding).
This is my conclusion form the graphs I showed here: disasters are an ancient myth! Just buy insurance! LOL








")








